Conversational Pathology Copilot
Turn the microscope
into a conversation.
Loupe is a chat-first copilot for whole-slide imaging. Ask while you read; it calls pathology vision models and literature tools, returning verifiable reasoning, structured quantification, and one-tap annotation drafts — pathologist always in control.
Loupe slide › manuscript
one clean workflow — slide to submission



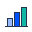


✓ Integrity-first — never fabricates datafigures watermarked · citations verified · AI disclosed
Why Loupe
Four reasons pathologists stay
Chat is the workflow
Ask in plain language; get answers backed by a visible tool trace.
Verifiable quantification
IHC positivity, H-score, differential & PubMed — rendered inline.
Agents, human-approved
Agents batch-draft; you accept/reject, with budgets & audit.
Governable
Adoption telemetry, cost & approval rate — measurable, tunable.
How a case moves through Loupe
One workflow, from slide intake to sign-out
Loupe isn’t a bag of features — it threads AI through the real diagnostic flow, with the pathologist deciding at every step.
01 Ingest & triage
Every slide is pre-read the moment it lands
Upload or import WSIs via DICOMweb. Loupe scores QC, writes a scan-time pre-read, and groups by organ — so you start with the slide that matters.
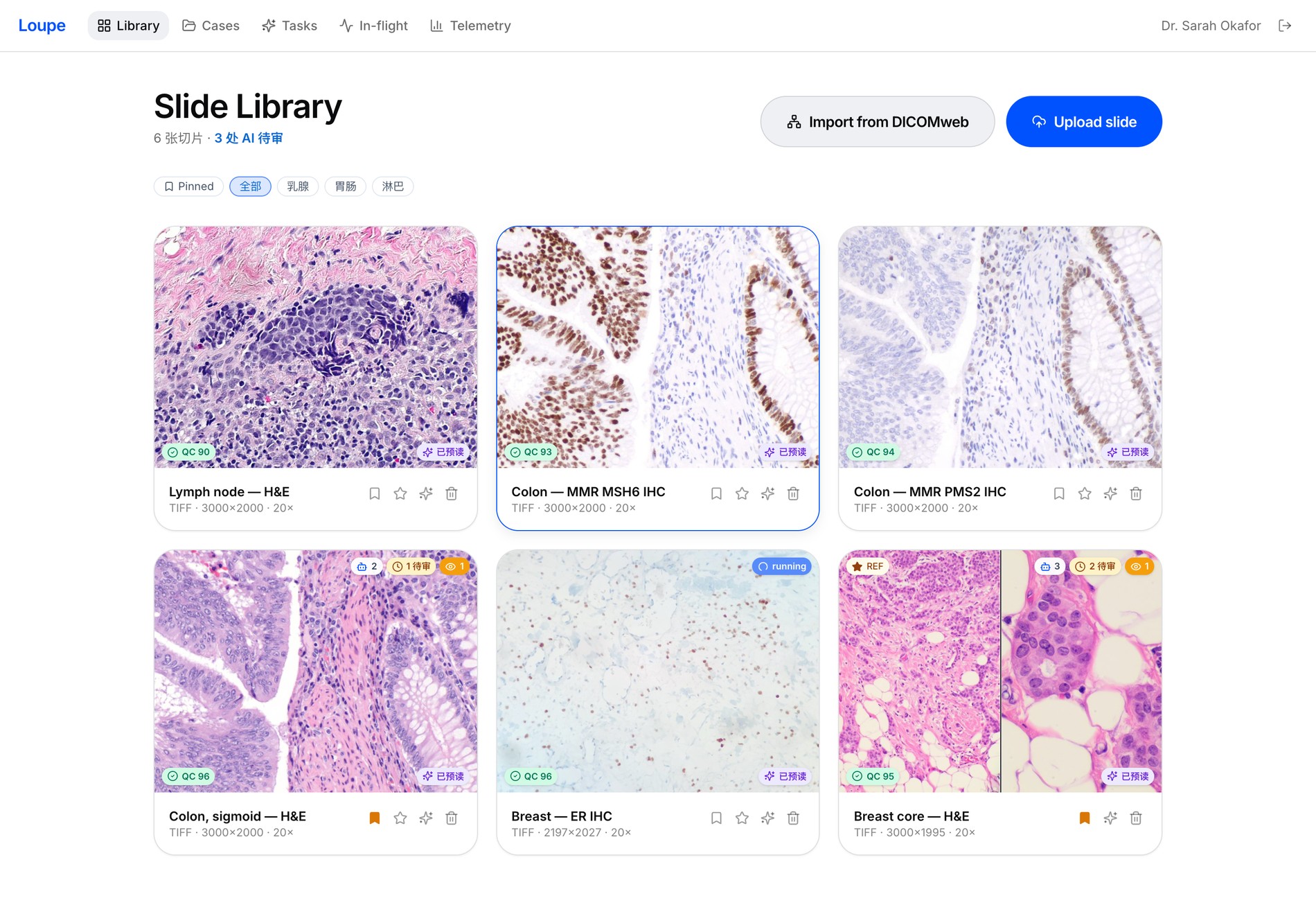
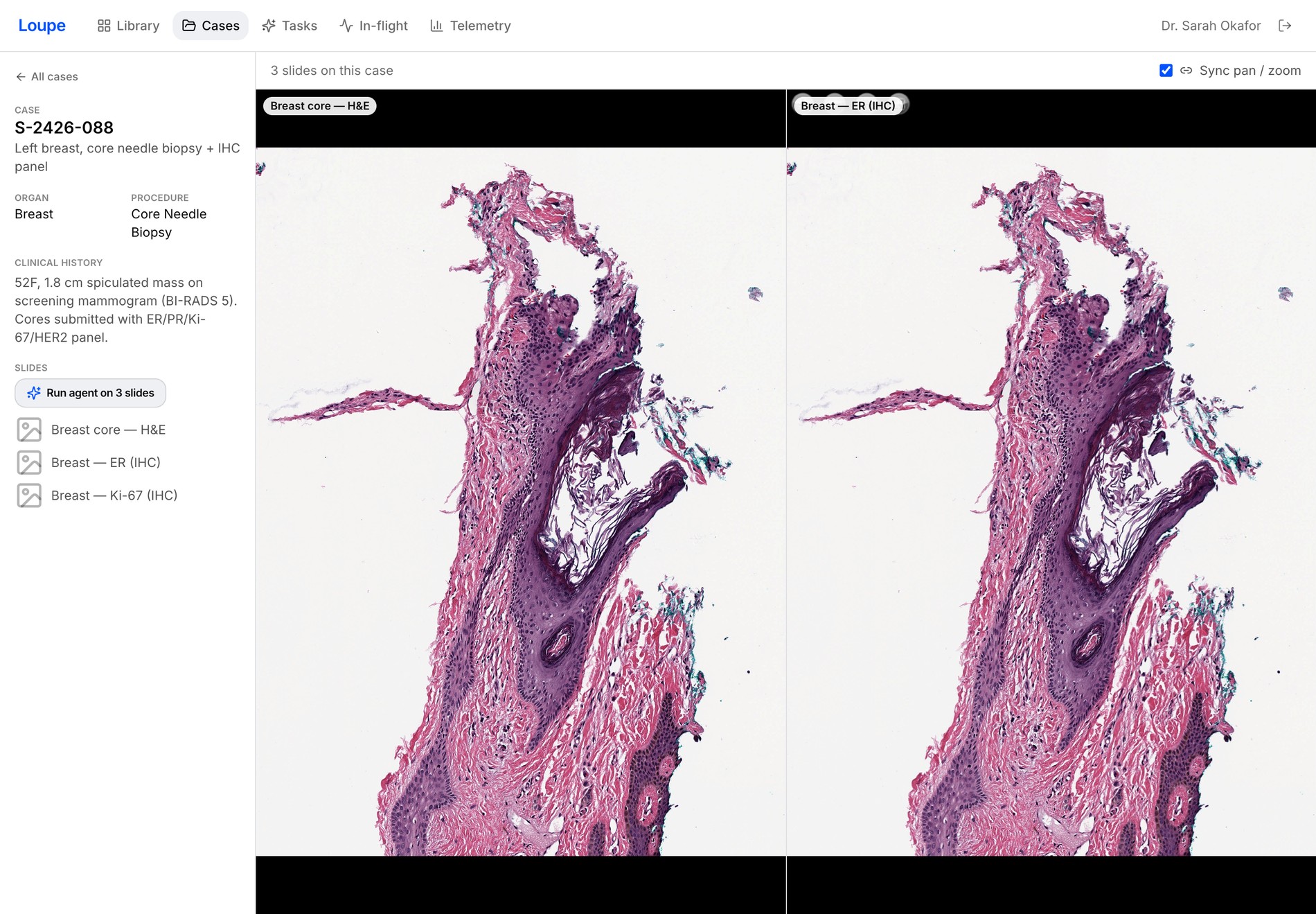
02 Conversational read-out
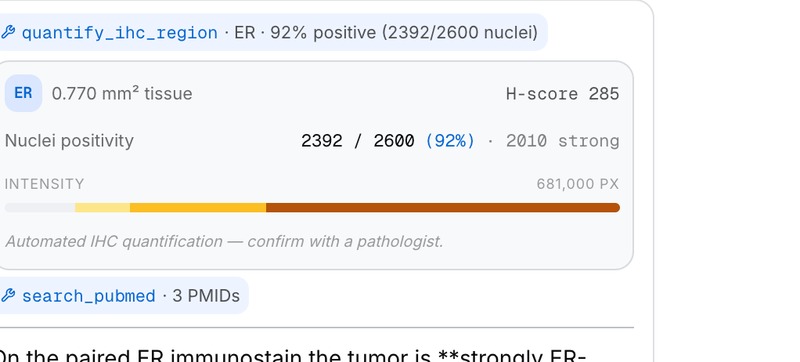
Ask in plain language, get an auditable answer
Select a region and ask. Loupe reads the tile, computes stats, quantifies IHC (e.g. ER 92%, H-score 285), cites PubMed, and shows the differential it weighed — not just a verdict.
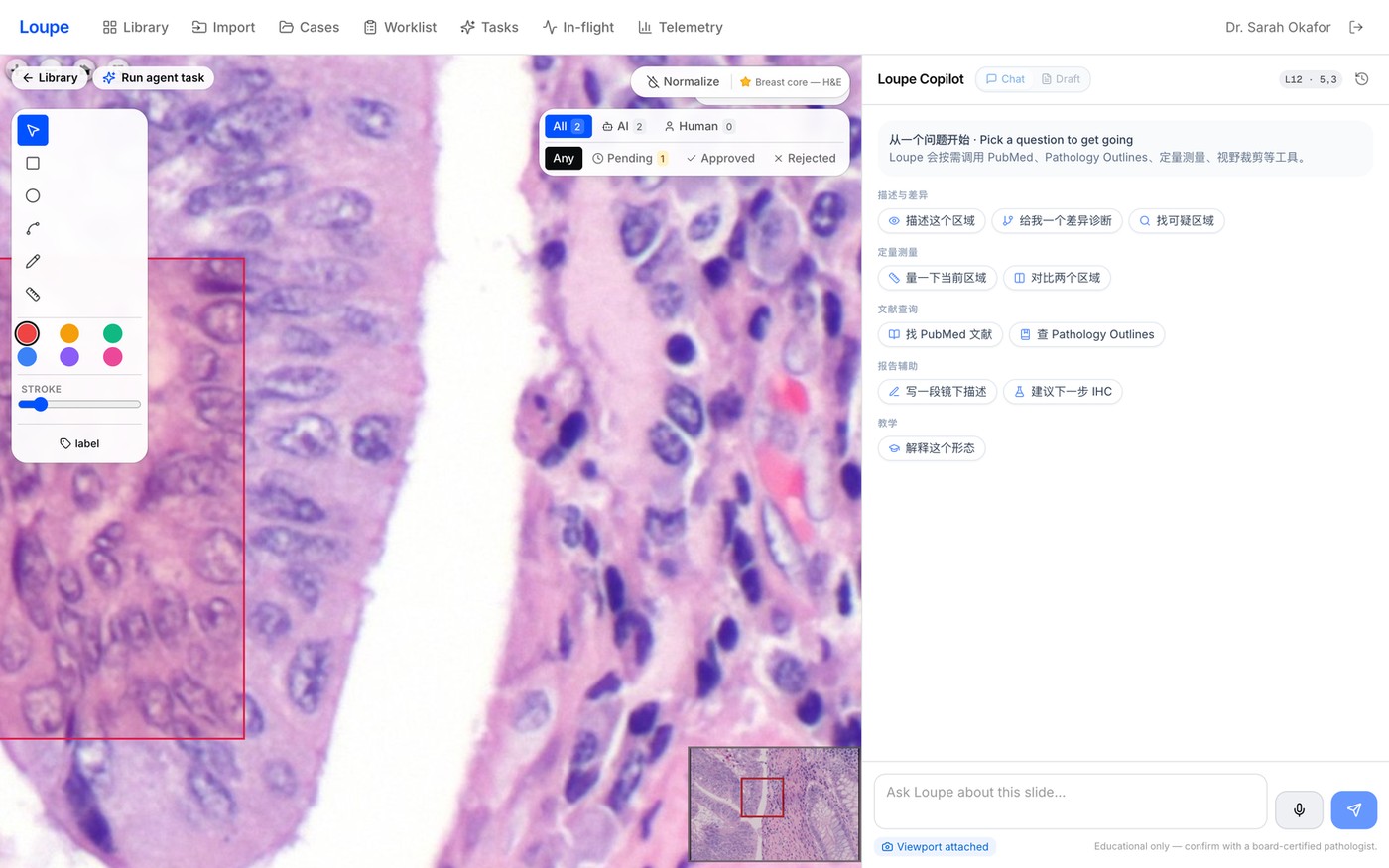
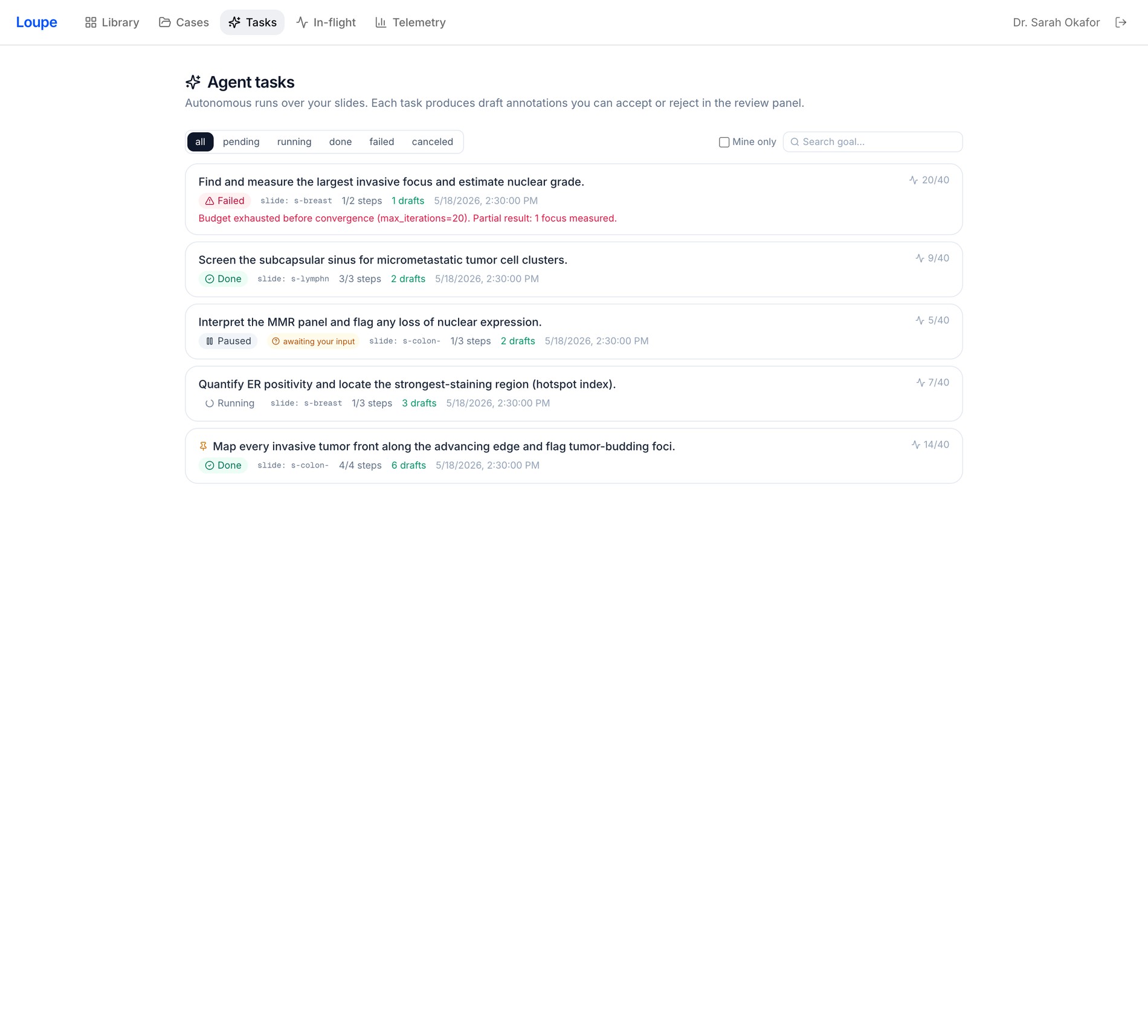
03 Autonomous agents
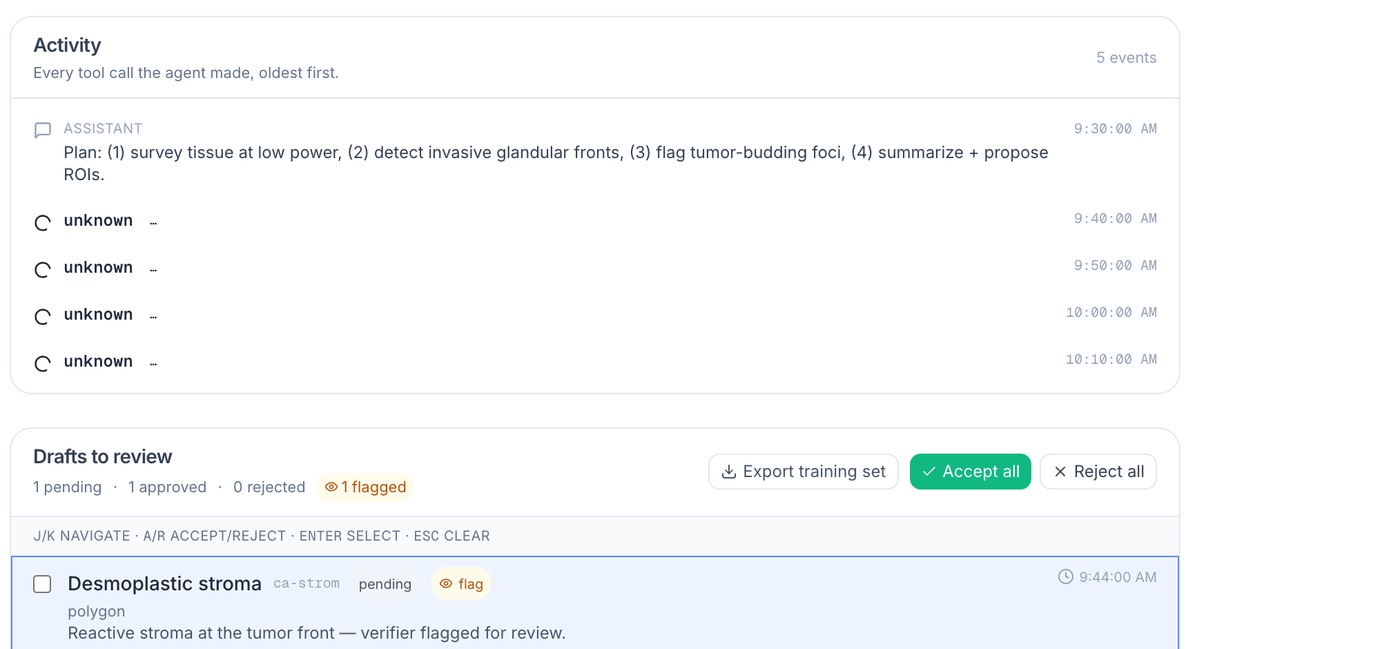
One sentence in, drafts out
“Map every invasive front and flag tumor budding.” The agent plans and runs within iteration / time / token budgets, drafting annotations per slide — dispatch across a whole case at once.
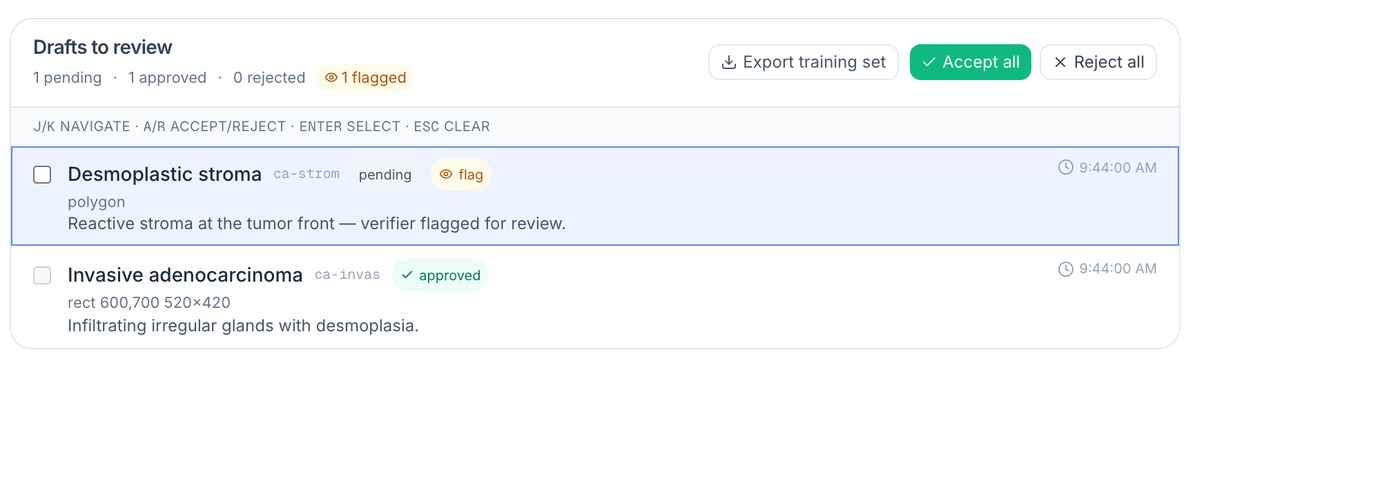
04 Human review & adopt
AI proposes, you decide
The task page shows the plan, budgets and activity trace; accept/reject drafts singly or in bulk, with a verifier surfacing low-confidence ones — and your reasons feed the next run.
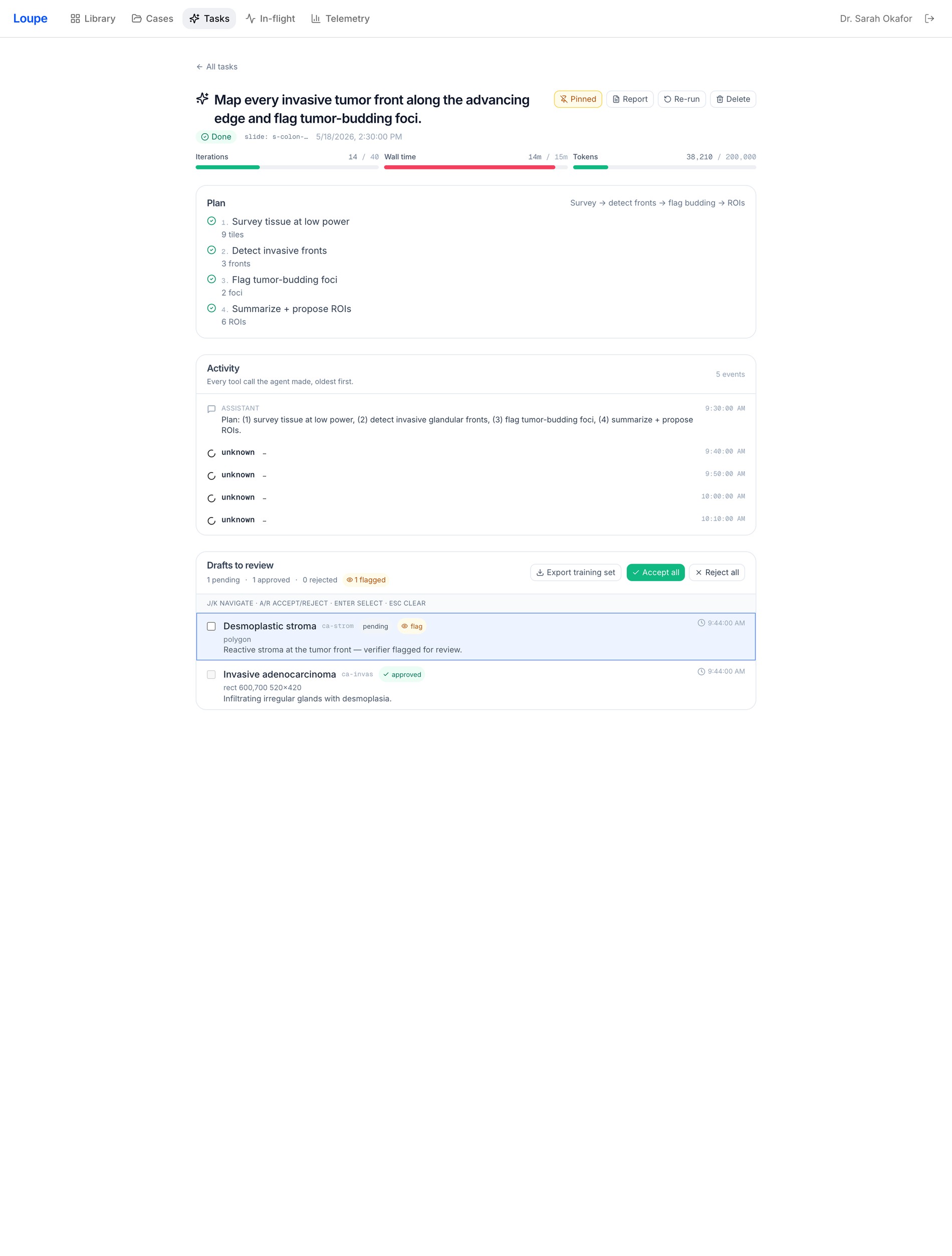
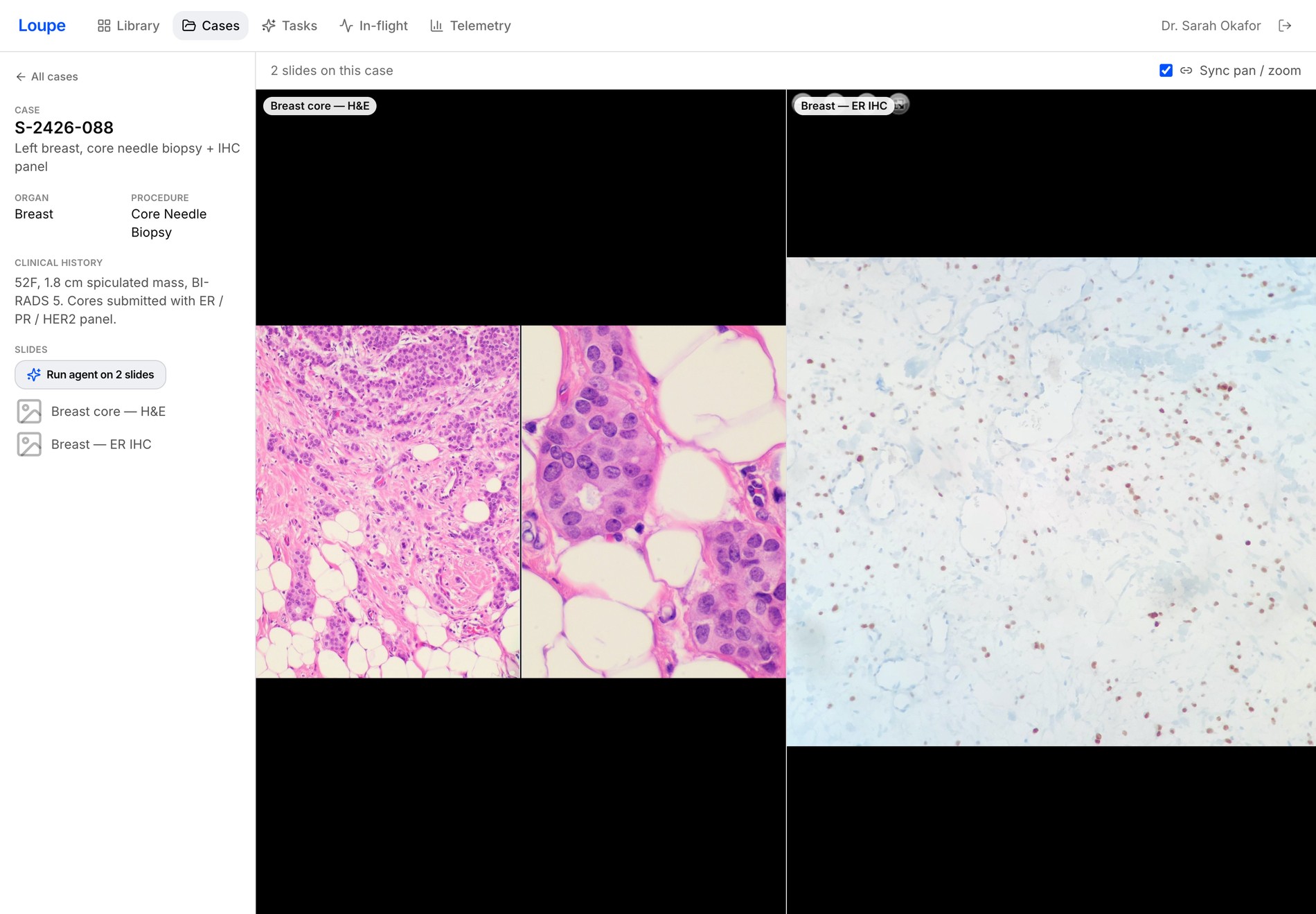
05 Compare in sync
H&E and IHC, side by side, in sync
Put a case’s slides (H&E + MMR PMS2/MSH6, or H&E + ER) into a pan/zoom-synced comparison — here MSH6 loss flags mismatch-repair deficiency for Lynch workup.
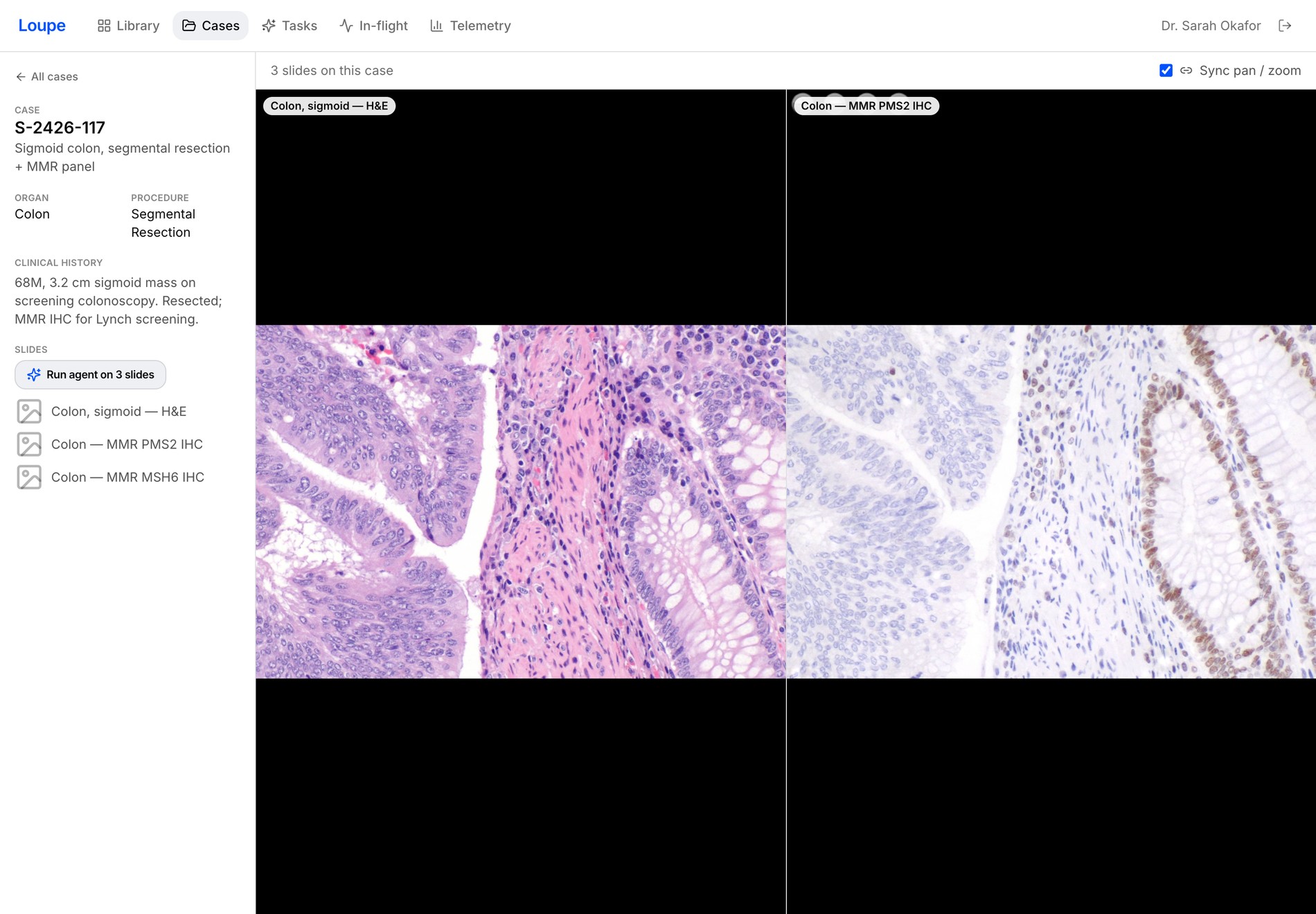
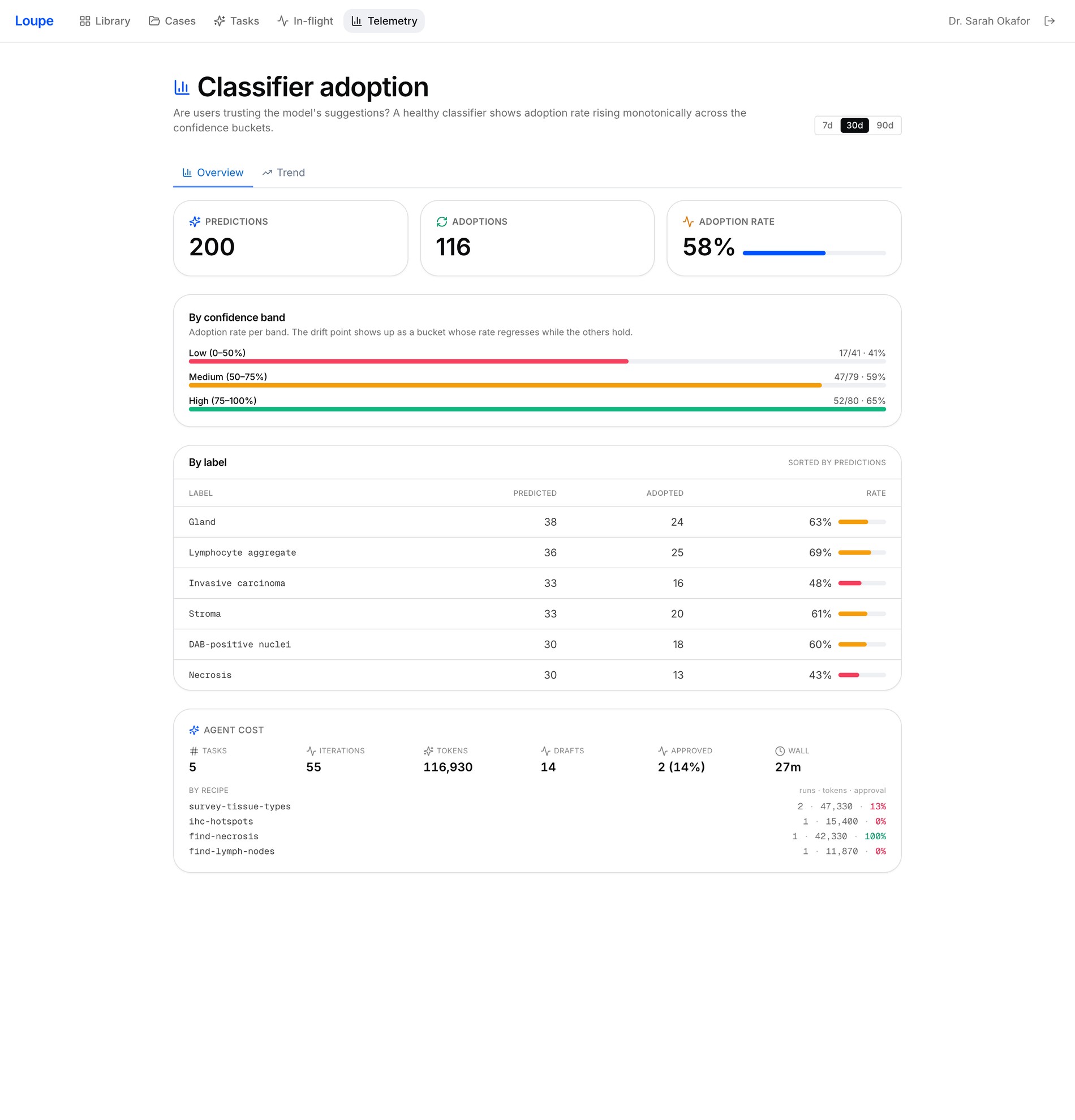
06 Telemetry & governance
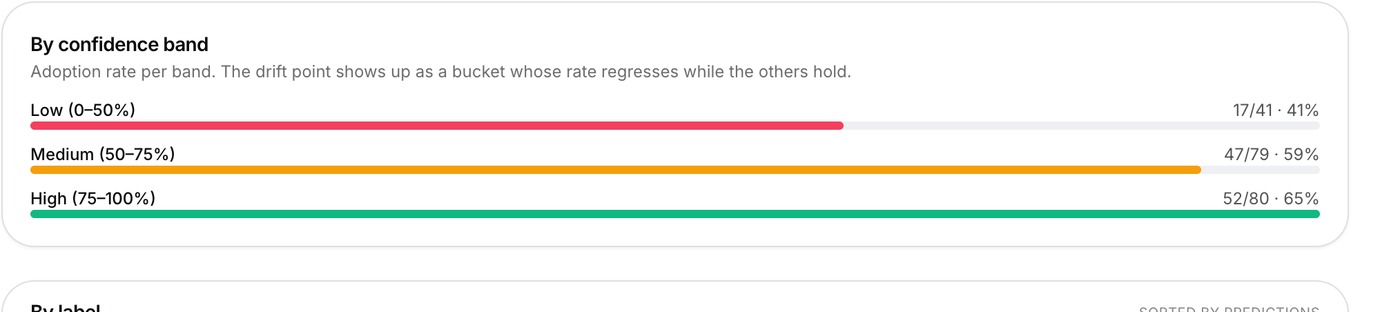
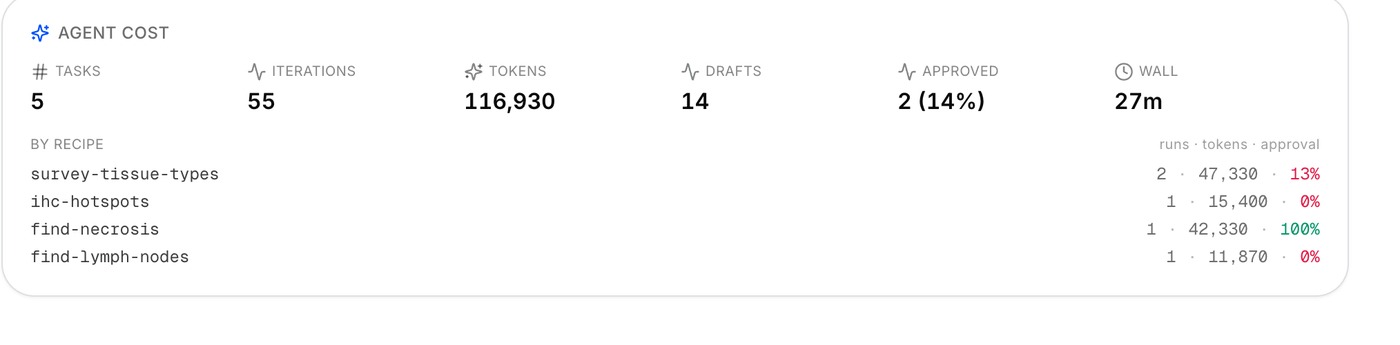
Quantify whether clinicians actually trust the AI
Track classifier adoption by confidence and over time, per-label acceptance, and agent cost & approval rate — so the whole deployment can be governed and tuned. Split-conformal calibration then turns your own reviewed predictions into a trust threshold: only predictions above it are badged "trusted", with the coverage stated honestly — never inflated.
A quick tour
Three screenshots, one quick look
All from the live product — click to enlarge.
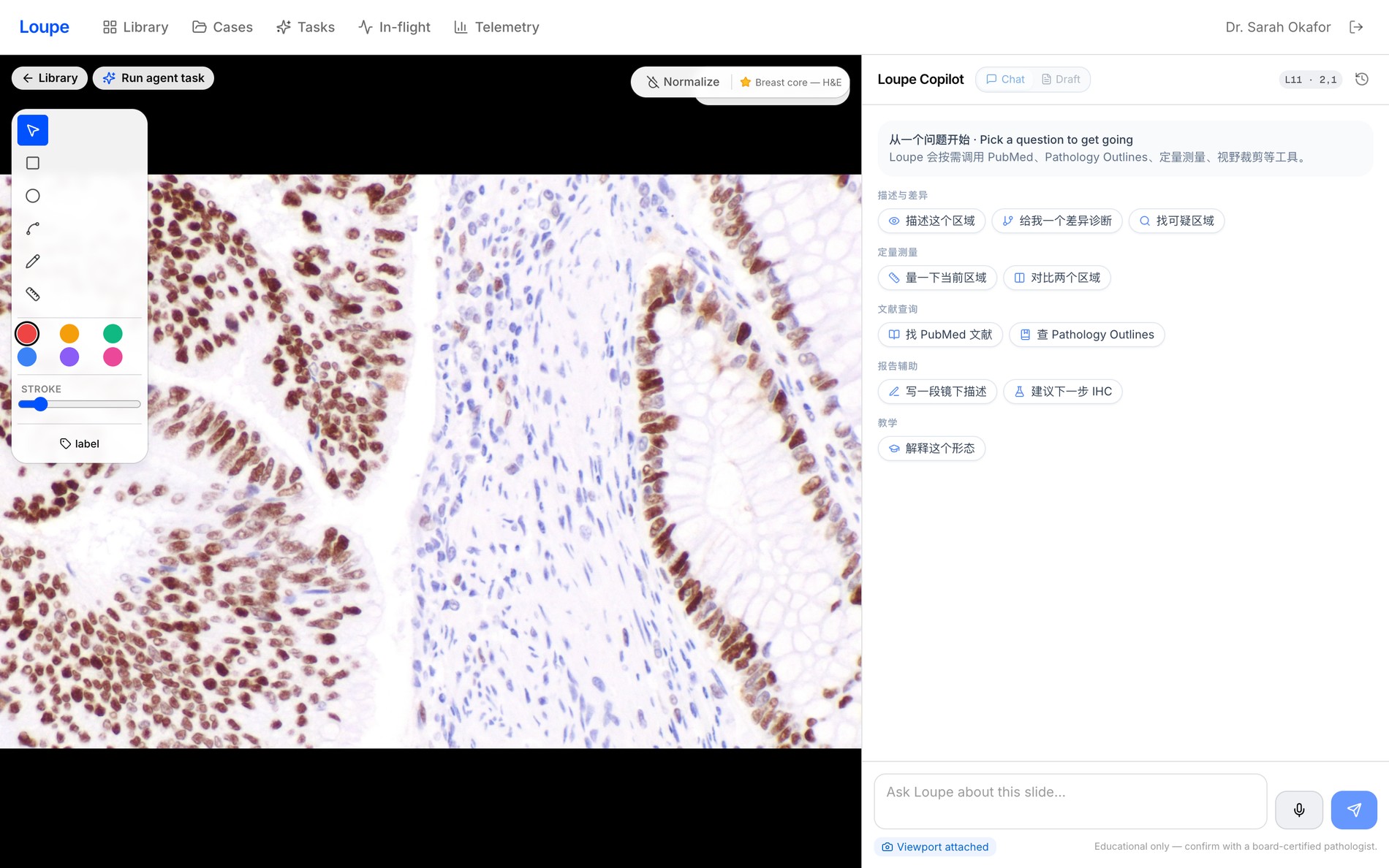
In detail
The load-bearing detail, up close
Uniform close-ups — every load-bearing number, clearly legible.
From cohort to manuscript
From a slide, all the way to submission
Loupe extends the diagnostic desk into a research desk — freeze a cohort, compute real statistics and publication-grade figures, draft the manuscript and grant, and run an integrity check before submission. It never fabricates data.
Real stats & figures
From a frozen cohort: ROC (DeLong 95% CI), calibration (Brier/ECE), Kaplan–Meier + log-rank, publication-rendered — insufficient data is left blank, not faked.
Predictions to figures
Turn real model predictions into evaluation figures + metrics, filed in the download center, reproducibly.
Pre-submission review
Every number is traced to the cohort’s real facts; unbacked performance claims are flagged as premature; an optional reviewer-2 critique on top.
Power & sample size
Standard formulas for two proportions/means, log-rank survival, single AUC — the sample-size justification reviewers and funders require.
NSFC format check
Audits an NSFC General-Program proposal against the official outline — sections, reference recency, length, AI-use disclosure.
Write & submit
Related-work synthesis, goal-directed rewrite (with an “introduced-number” check), .bib/CSL export, journal matching, Markdown→LaTeX / Word.
The real differentiator is integrity: illustrative figures are watermarked, citations are verified, and AI use is disclosed — aligned with the new NIH / NSF rules on AI in papers and grants.
Measured, not claimed · RUO
Real numbers, from real runs
We ran the newest Gemini (gemini-3.5-flash) directly on open, gold-labeled real pathology images — including real TCGA whole-slides. Real model, real data, gold-standard grading, reported as-is.
| Experiment | Data (open) | Result |
|---|---|---|
| Real TCGA whole-slide · cancer-type ID (8-way) | GDC open-access .svs · OpenSlide | 7 / 8 (chance 12.5%) |
| Lymph-node metastasis (balanced, N=100) | PatchCamelyon | 85% · sensitivity 0.94 |
| Pathology yes/no VQA (N=100) | PathVQA | 79% |
It names most cancers from real slides with zero refusals — but over-calls positives and still misses some, so it is a triage / pre-read aid, not a replacement for diagnosis. A stronger pro model was no better; flash suffices.
⚠ Research evaluation (RUO): small samples, closed-set multiple choice — not clinical validation, not for diagnostic decisions.
Editions & deploy
One codebase, two editions, deploy anywhere
Async FastAPI + SQLAlchemy, React 19 + OpenSeadragon, OpenSlide pipeline, pluggable multi-LLM; Docker / GPU / HTTPS deploys and DICOMweb import.
| Capability | Commercial | Education |
|---|---|---|
| Chat read-out · annotations · report draft | ✓ | ✓ |
| Structured synoptic reports (CAP: GI / breast / prostate) + HL7 v2 / FHIR R4 export | ✓ | ✓ |
| Agents · telemetry · comparison | ✓ | ✓ |
| Research authoring · stats/figures · pre-submission review · NSFC check | ✓ | ✓ |
| Pathology foundation models UNI / CONCH | — | ✓ (CC-BY-NC-ND) |
| Similar-tile search | color/texture fingerprint | ✓ UNI embeddings |
| Image / use | smallest · cloud-defensible | weights baked · non-commercial |
Pluggable LLMs
Gemini / OpenAI / MiniMax / Kimi via one compatible layer.
Security & audit
JWT auth, rate-limit, full audit log, per-case audit timeline, TLS proxy.
Open WSI & interop
OpenSlide formats · DZI tiles · DICOMweb import · FHIR/HL7 report export.